
 Diretrizes para Submissão de Amostras
Diretrizes para Submissão de Amostras
O que é o Drug-seq? Guia de Transcriptómica de Alta Vazão
O DRUG-seq muda a forma como os investigadores abordam a descoberta de medicamentos. O método elimina a extração de RNA e funciona com apenas 1.000 células. Permite uma alta capacidade de processamento. Sequenciação de RNA para triagens em larga escala a uma fração dos custos tradicionais. Os utilizadores podem escolher entre pacotes de serviços flexíveis, incluindo Sequenciação de Transcritos de Comprimento Total para uma análise mais profunda. O DRUG-seq deteta até 12.000 genes com apenas 2–13 milhões de leituras por poço, conforme mostrado na tabela abaixo.
| Métrico | DRUG-seq (2 milhões de leituras/poço) | DRUG-seq (13 milhões de leituras/poço) | RNA-seq populacional (média) |
|---|---|---|---|
| Genes Detetados | 11.000 | 12.000 | 17.000 |
| Profundidade de Leitura | 2 milhões | 13 milhões | 42 milhões |

O DRUG-seq apoia a descoberta de biomarcadores, análise de mecanismos e medicina de precisão. A plataforma oferece soluções económicas e escaláveis para a pesquisa farmacêutica moderna.
Principais Conclusões
-
Drug-seq elimina a extração de RNA., permitindo que os investigadores analisem a expressão génica diretamente a partir de lisados celulares.
-
A plataforma pode funcionar com apenas 1.000 células, tornando-a ideal para amostras raras e pequenos cortes de tecido.
-
O Drug-seq deteta até 12.000 genes com apenas 2 a 13 milhões de leituras por poço, proporcionando uma visão abrangente da expressão génica.
-
Este método é rentável, com custos de sequenciação em torno de 3 dólares por amostra, significativamente mais baixos do que o RNA-seq tradicional.
-
O Drug-seq suporta triagens de alto rendimento, permitindo que os investigadores testem centenas a milhares de compostos em paralelo.
-
A tecnologia melhora a descoberta de biomarcadores e a análise de mecanismos, ajudando as equipas a tomar decisões informadas no desenvolvimento de medicamentos.
-
Tempos de resposta rápidos, tão curtos quanto 10 dias úteis, aceleram os processos de investigação e tomada de decisão.
-
A CD Genomics oferece pacotes de serviços flexíveis, permitindo que os investigadores escolham opções que se adequem às necessidades específicas dos seus projetos.
Gargalos na Descoberta de Fármacos
Limites do HTS Tradicional
A descoberta de fármacos depende da triagem de alto rendimento (HTS) para identificar compostos promissores. Os métodos tradicionais de HTS utilizam automação e miniaturização para testar rapidamente milhares ou milhões de compostos. Esta abordagem acelera a identificação de hits iniciais e aumenta a eficiência dos pipelines de desenvolvimento de fármacos. No entanto, esses métodos ainda enfrentam vários desafios.
O HTS tradicional muitas vezes limita o número de compostos que os investigadores podem testar. Esta restrição pode causar oportunidades perdidas, uma vez que alguns potenciais candidatos a fármacos podem nunca chegar à fase de triagem. Muitas plataformas de HTS concentram-se em endpoints únicos, como a viabilidade celular ou a atividade enzimática. Estas leituras não capturam a complexidade total das respostas celulares. Como resultado, os investigadores podem negligenciar mudanças importantes na expressão genética que sinalizam toxicidade ou efeitos fora do alvo.
Outro desafio envolve o custo e o tempo necessários para ecrãs em grande escala. Mesmo com a automação, os HTS tradicionais podem tornar-se caros e intensivos em mão-de-obra ao serem ampliados. A necessidade de equipamento especializado e pessoal qualificado aumenta a carga. Estes fatores desaceleram o ritmo da descoberta de medicamentos e limitam a taxa de sucesso dos projetos.
Necessidade de Transcriptómica Escalável
A pesquisa farmacêutica moderna exige dados mais abrangentes. Estudos de transcriptómica de alta complexidade proporcionam uma compreensão mais profunda de como os compostos afetam a expressão génica em todo o transcriptoma. Drug-seq aborda esta necessidade ao permitir transcriptómica escalável e de alto rendimento para a descoberta de fármacos.
-
A fusão multimodal em transcriptómica integra diversos tipos de dados, oferecendo uma visão completa dos resultados experimentais.
-
Esta integração suporta análises avançadas, como a avaliação da toxicidade de fármacos e a comparação de linhagens celulares de cancro.
-
A transcriptómica espacial combina técnicas histológicas com sequenciação de RNA de alto rendimento.Este método preserva a informação espacial, que é crucial para entender a heterogeneidade tecidual e celular.
-
Os investigadores podem explorar padrões de expressão genética espacial, identificar genes assinatura para tipos celulares específicos e estudar interacções intercelulares.
O Drug-seq torna estas abordagens avançadas acessíveis. Permite que os cientistas perfilhem a expressão génica a partir de apenas 1.000 células, tornando-o adequado para amostras raras e organoides. A plataforma suporta centenas a milhares de tratamentos com fármacos ou perturbações genéticas em paralelo. Os investigadores obtêm insights sobre o mecanismo de ação, descoberta de biomarcadores e medicina personalizada.
O Drug-seq simplifica os fluxos de trabalho ao eliminar a extração de RNA e reduzir os tempos de resposta. Esta eficiência ajuda as equipas farmacêuticas a acelerar a descoberta e a melhorar a qualidade dos dados.
Com a transcriptómica escalável, o drug-seq capacita os investigadores a ultrapassar gargalos tradicionais e a impulsionar a inovação no desenvolvimento de medicamentos.
O que é o Drug-seq?
Drug-seq constitui uma plataforma transformadora para transcriptómica de alto rendimento na descoberta de medicamentos. Os investigadores utilizam o drug-seq para realizar análises do transcriptoma completo diretamente a partir de lisados celulares, organoides ou cortes de tecido. Este método elimina a necessidade de extração de RNA e suporta a perfuração a partir de apenas 1.000 células. A CD Genomics oferece pacotes de serviços flexíveis, incluindo opções padrão, de ultra-baixa entrada e de transcritos de comprimento completo. Estes pacotes atendem a diversas necessidades de investigação, desde triagens de compostos em grande escala até caracterização molecular profunda.
Metodologia Fundamental
Drug-seq aproveita o perfilamento transcricional em todo o genoma para triagem de compostos de forma eficiente. A plataforma deteta mais de 10.000 genes diretamente, proporcionando uma visão abrangente das alterações na expressão génica. Os investigadores beneficiam de uma agrupamento preciso e da identificação de genes diferenciais únicos. O Drug-seq suporta a análise do mecanismo de ação e a enriquecimento de vias, incluindo funções mitocondriais. A tabela abaixo destaca as principais diferenças metodológicas. entre drug-seq e outras plataformas de transcriptómica:
| Recurso | Drug-seq | L1000/RASL-seq |
|---|---|---|
| Custo | Significativamente reduzido | Custo mais elevado |
| Rendimento | Alto rendimento | Menor rendimento |
| Medição Direta | >10.000 genes medidos diretamente | Medições inferidas para muitos genes |
| Precisão da Agrupamento | Agrupamento mais preciso | Agrupamento menos preciso |
| Genes Diferenciais Únicos | 1351 genes não detetados pelo L1000 | Deteção limitada |
| Enriquecimento de Vias Metabólicas | Funções das mitocôndrias, etc. | Caminhos menos abrangentes |
Drug-seq emprega clustering hierárquico e análise do mecanismo de açãoTambém incorpora mapeamento de conectividade para inferir perfis de mRNA, apoiando uma interpretação robusta dos dados.
Lise Direta e Multiplexação
O Drug-seq simplifica os fluxos de trabalho ao utilizar lise celular direta. Esta abordagem preserva a integridade da amostra e reduz o tempo de manuseio. A multiplexação permite a análise de centenas a milhares de amostras em paralelo. Os investigadores podem perfilar amostras clínicas raras, organoides ou fatias de tecido com um input mínimo. O serviço de ultra-baixo input da CD Genomics funciona com tão poucos quanto 1.000 células, tornando o drug-seq adequado para amostras preciosas ou limitadas.
Dica: A lise direta e a multiplexação não só economizam tempo, mas também reduzem custos, tornando o drug-seq acessível para estudos em grande escala.
Evolução do Drug-seq
A evolução do drug-seq reflete avanços em tecnologias de sequenciação e de célula únicaEm 2009, o sequenciamento de RNA de célula única começou a impactar a pesquisa farmacêutica. Melhorias subsequentes permitiram uma compreensão mais profunda da genómica e do desenvolvimento de medicamentos. Hoje, o drug-seq integra esses avanços, apoiando a identificação de alvos, a seleção de candidatos e a pesquisa clínica. A plataforma continua a expandir as suas aplicações em neurociência, oncologia e medicina personalizada.
Os investigadores agora dependem do drug-seq para a caracterização do transcriptoma de forma escalável, precisa e económica. A tecnologia permite às equipas acelerar a descoberta e obter informações acionáveis a partir da análise do transcriptoma completo.
Fluxo de Trabalho Drug-seq
Lise celular e captura de RNA
O Drug-seq começa com um processo simplificado de lise celular e captura de RNA. Os investigadores preparam células, organoides ou lisados de tecido diretamente, pulando a etapa tradicional de extração de RNA. Esta abordagem preserva a integridade do RNA e reduz o tempo de manuseio. O Drug-seq permite uma análise imparcial. perfilamento de transcriptoma completo a partir de apenas 1.000 células. O método suporta centenas de amostras em um único experimento, tornando-o ideal para triagens de fármacos em alta capacidade.
O método de lise direta do Drug-seq reduz custos e permite a análise de amostras raras ou preciosas. A multiplexação aumenta ainda mais a eficiência, permitindo que os cientistas processem muitas amostras de uma só vez.
RT e Codificação de Barras
A transcrição reversa (RT) e a codificação por código de barras constituem o próximo passo crítico no fluxo de trabalho do drug-seq. Durante a RT, o sistema converte o RNA capturado em DNA complementar (cDNA). Cada amostra recebe um código de barras único, que codifica as condições de tratamento e a identidade da amostra. Esta codificação precisa garante o rastreamento preciso de cada amostra ao longo do processo.
-
A estratégia de codificação de barras no drug-seq permite que os investigadores agrupem amostras com base nos tratamentos com medicamentos.
-
Códigos de barras funcionais representam combinações de medicamentos, apoiando uma análise de dados robusta.
-
Estudos mostram que este método não introduz viés, uma vez que a agrupamento por combinação de medicamentos resulta em pontuações de silhueta mais altas do que o agrupamento aleatório.
Estratégia de Duplo Índice
O Drug-seq utiliza uma estratégia de dupla indexação para melhorar ainda mais a identificação das amostras. Cada amostra recebe dois índices únicos, um para a placa e outro para o poço. Este sistema dual permite o processamento simultâneo de centenas ou milhares de amostras. Também reduz o risco de erro na identificação das amostras e de contaminação cruzada.
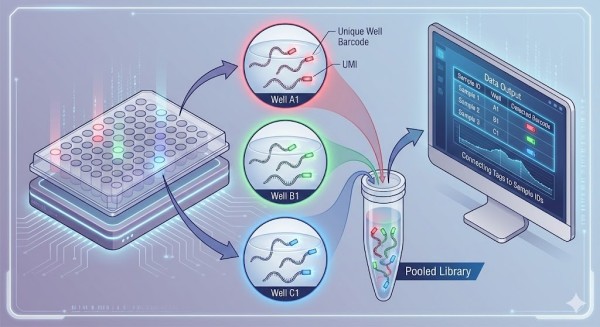
Figura 2: O Poder do Multiplexing: Estratégia de Codificação de Duplo Índice. Cada poço é atribuído uma combinação única de Códigos de Barras de Poço e Códigos de Barras de Placa durante a Transcrição Reversa (RT). Após a mistura, Identificadores Moleculares Únicos (UMIs) são utilizados para eliminar o viés de duplicação da PCR, garantindo uma quantificação precisa dos genes para cada amostra.
Códigos de Barras Moleculares Explicados
Códigos de barras moleculares desempenham um papel fundamental no drug-seq. Os códigos de barras moleculares são sequências curtas adicionadas a cada molécula de RNA antes da amplificação. Eles ajudam a distinguir entre moléculas originais e duplicados de PCR. Esta característica melhora a precisão dos dados e garante uma quantificação fiável da expressão génica.
Agrupamento e Sequenciação de Bibliotecas
Após a codificação de barras, o drug-seq agrupa todas as bibliotecas para sequenciação. Agrupamento otimiza custos e aumenta o poder estatísticoAo combinar amostras, os investigadores reduzem a variabilidade dentro do grupo e detetam efeitos biológicos com menos amostras. A agregação também ajuda a gerir o ruído de genes de baixa abundância, tornando a análise de expressão gênica diferencial mais robusta.
O fluxo de trabalho do Drug-seq suporta sequenciação escalável e de alto rendimento. A seleção cuidadosa do tamanho do pool e da profundidade de sequenciação garante dados de alta qualidade. A CD Genomics entrega resultados rapidamente, com prazos de entrega padrão tão rápidos quanto 10 dias úteis. A sua equipa dedicada de bioinformática fornece análise e relatórios de dados abrangentes, apoiando cada etapa do processo de drug-seq.
| Passo | Descrição |
|---|---|
| 1 | Preparação de Amostras: Prepare células, organoides ou lisados de tecido sem extração de RNA. |
| 2 | Envio de Amostra: Envie placas ou lisados congelados para o centro de serviços. |
| 3 | Preparação da Biblioteca: Atribuir códigos de barras e construir bibliotecas de sequenciação. |
| 4 | Ponto de Controlo de Qualidade: Avaliar a qualidade da biblioteca antes do sequenciamento profundo. |
| 5 | Sequenciação Profunda: Realizar sequenciação de alto rendimento adaptada aos objetivos experimentais. |
| 6 | Análise de Dados e Relatórios: Alinhar leituras e gerar matrizes de contagem de genes. |
| sete | Entrega de Dados: Entregar todos os dados de forma segura, incluindo arquivos FASTQ e resumos de alinhamento. |
O fluxo de trabalho eficiente do Drug-seq, desde a lise celular até à entrega de dados, acelera a descoberta e apoia projetos de transcriptómica em grande escala.
Pipeline de Bioinformática
O Drug-seq gera grandes volumes de dados de transcriptómica. A CD Genomics oferece um robusto pipeline de bioinformática para ajudar os investigadores a interpretar os resultados de forma rápida e precisa. O pipeline começa após o sequenciamento e continua através de várias etapas analíticas. Os investigadores recebem apoio em cada etapa, garantindo dados de expressão génica de alta qualidade para a descoberta de fármacos.
O processo começa com o controlo de qualidade. Os analistas examinam os dados de sequenciação quanto ao comprimento das leituras e à precisão das chamadas de bases. Esta etapa garante que apenas dados fiáveis avancem. Segue-se o controlo de qualidade do alinhamento. A equipa mapeia as leituras ao genoma de referência e verifica a completude. O mapeamento preciso é essencial para perfis de expressão génica fiáveis.
A análise quantitativa da expressão génica vem a seguir. Algoritmos calculam a abundância de transcritos utilizando valores normalizados, como TPM (Transcritos Por Milhão). Esta abordagem permite que os investigadores comparem a expressão génica entre amostras e condições. A análise diferencial da expressão génica identifica genes que mudam significativamente entre grupos tratados e de controlo. Estes resultados revelam como os compostos afetam as vias celulares.
A análise de vias fornece insights mais profundos. Os analistas utilizam métodos de enriquecimento para encontrar vias biológicas alteradas pelo tratamento com medicamentos. Esta informação ajuda os investigadores a compreender os mecanismos de ação e a identificar potenciais biomarcadores.
A tabela abaixo resume o principais etapas do fluxo de trabalho de bioinformática Drug-seq:
| Aspecto do Serviço | Descrição |
|---|---|
| Controlo de Qualidade | Avaliação abrangente da qualidade dos dados de sequenciação, incluindo comprimento das leituras e precisão das chamadas de bases. |
| Controlo de Qualidade de Alinhamento | Avaliação dos resultados de alinhamento para garantir a precisão e a completude das leituras mapeadas ao genoma. |
| Análise Quantitativa da Expressão Génica | Cálculo da abundância de transcritos utilizando algoritmos para níveis de expressão normalizados (por exemplo, TPM). |
| Análise de Expressão Génica Diferencial | Identificação de genes com alterações significativas na expressão entre condições (por exemplo, tratado vs. controlo). |
| Análise de Caminhos | Análise de enriquecimento de genes diferencialmente expressos para identificar vias alteradas devido ao tratamento com fármacos. |
Os investigadores beneficiam de um fluxo de trabalho simplificado que elimina a extração de RNA e reduz o tempo de manuseio. O pipeline de bioinformática transforma leituras de sequenciamento brutas em matrizes de expressão génica acionáveis. O Drug-seq permite a descoberta imparcial e suporta triagens em alta capacidade para investigação farmacêutica.
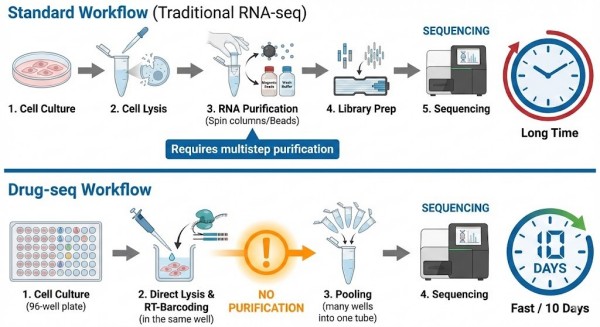
Figura 1: Fluxo de Trabalho Drug-seq Simplificado vs. RNA-seq Tradicional. Ao contrário dos métodos tradicionais que exigem purificação de RNA intensiva em mão de obra, o Drug-seq utiliza uma abordagem de lise direta. As amostras são lisadas, codificadas com códigos de barras e agrupadas imediatamente, permitindo o processamento em alta capacidade de milhares de poços em paralelo.
Vantagens do Drug-seq
Descoberta Imparcial
O Drug-seq permite que os investigadores para explorar alterações na expressão génica sem viés. A plataforma analisa milhares de genes diretamente a partir de lisados celulares. Os cientistas podem identificar novos mecanismos de ação e potenciais alvos de fármacos. Estudos publicados confirmam o poder desta abordagem.
| Referência de Estudo | Resultados | Implicações |
|---|---|---|
| Ye et al. (2018) | Identificou quatro clusters funcionais: sinalização, tradução, epigenética e ciclo celular. | Mostra que o drug-seq pode revelar mecanismos de ação e alvos de fármacos. |
| Ye et al. (2018) | Comparou os resultados com a base de dados do Connectivity Map, confirmando que 52 dos 433 compostos corresponderam. | Valida os resultados do drug-seq com conjuntos de dados independentes. |
| Li et al. (2022) | Relatórios de resultados de atividade biológica imparcial para a descoberta de fármacos em neurociência. | Suporta drug-seq em diversos projetos de descoberta de fármacos. |
Os investigadores utilizam o drug-seq para descobrir assinaturas genéticas e alterações em vias metabólicas. O método funciona bem para a análise de mecanismos e descoberta de biomarcadores. Apoia estudos em neurociência, oncologia e medicina personalizada.
O Drug-seq fornece uma visão abrangente das respostas celulares, ajudando as equipas a tomar decisões informadas no início do desenvolvimento de medicamentos.
Custo e Eficiência de Amostras
O Drug-seq reduz tanto os custos como os requisitos de amostra. A plataforma elimina a extração de RNA e utiliza lise direta. Esta abordagem poupa tempo e preserva a integridade da amostra. Os investigadores podem perfilar a expressão génica a partir de apenas 1.000 células.
-
O custo de preparação de bibliotecas NGS com kits tradicionais é de cerca de 45 a 47 dólares por amostra.
-
O BOLT-seq, um método relacionado, prepara até 96 bibliotecas em 4 horas, com apenas 2 horas de tempo de manuseio.
-
O BOLT-seq utiliza lisados celulares não purificados e omite etapas de purificação, reduzindo o tempo e o custo.
O Drug-seq segue um fluxo de trabalho semelhante e simplificado. Os cientistas podem processar amostras raras ou preciosas, como organoides ou biópsias clínicas. O método suporta estudos em grande escala sem altos custos.
A rápida resposta e as baixas necessidades de entrada tornam o drug-seq ideal para triagens de alto rendimento e projetos com material limitado.
Triagem de Alto Rendimento
O Drug-seq suporta triagem de alto rendimento para a descoberta de fármacos. A plataforma processa centenas a milhares de amostras em paralelo. Os investigadores podem testar muitos compostos ou perturbações genéticas de uma só vez.
-
TORNADO-seq, outra plataforma de alto rendimento, utiliza sequenciação de RNA direcionada para estudar organoides.
-
O TORNADO-seq pode analisar misturas celulares e estados de diferenciação, melhorando os estudos de eficácia de medicamentos.
O Drug-seq corresponde a estas forças. Permite uma transcriptómica escalável e rentável para grandes bibliotecas de compostos. Os cientistas obtêm informações sobre os efeitos dos medicamentos, toxicidade e respostas fora do alvo.
O Drug-seq acelera a descoberta ao combinar rapidez, escalabilidade e robustez na qualidade dos dados.
Drug-seq vs. RNA-seq
Diferenças na Preparação de Bibliotecas
Drug-seq A sequenciação de RNA desempenha um papel importante na descoberta de medicamentos. No entanto, os seus fluxos de trabalho diferem em aspectos-chave. O Drug-seq utiliza uma abordagem de lise direta. Este método omite a etapa de extração de RNA. Os investigadores podem adicionar lisados celulares diretamente ao fluxo de trabalho. A sequenciação de RNA, por outro lado, requer uma extração cuidadosa de RNA de cada amostra. Esta etapa acrescenta tempo e complexidade.
A tabela abaixo destaca as principais diferenças na preparação de bibliotecas:
| Recurso | Drug-seq | RNA-seq |
|---|---|---|
| Adequação do Tipo de Amostra | Adequado para lisados celulares sem extração. | Requer extração de RNA de amostras. |
| Passos de Extração de RNA | Eliminado | Requerido |
| Rendimento da Amostra | Alto, pode processar centenas simultaneamente. | Vazão limitada devido aos passos de extração |
| Eficiência de Custos | Mais baixo devido a menos etapas | Mais elevado devido aos custos de extração e limpeza. |
O Drug-seq permite que os investigadores processem centenas de amostras de uma só vez. Este elevado rendimento torna-o ideal para triagens em grande escala. A sequenciação de RNA muitas vezes limita o rendimento porque cada amostra necessita de extração e purificação. O Drug-seq também reduz o risco de perda ou degradação de amostras. O fluxo de trabalho otimizado poupa tempo e recursos.
Dica: A lise direta em drug-seq preserva a qualidade do RNA e acelera o processo. Esta característica beneficia estudos com amostras raras ou preciosas.
Profundidade e Cobertura
A profundidade de leitura e a cobertura são fatores importantes na transcriptómica. O sequenciamento de RNA utiliza tipicamente sequenciamento profundo para capturar o transcriptoma completo. Os investigadores podem sequenciar cada amostra com 30 a 50 milhões de leituras. Esta abordagem deteta transcritos raros e proporciona uma ampla cobertura.
O drug-seq utiliza uma estratégia mais direcionada. A maioria dos experimentos requer apenas de 2 a 13 milhões de leituras por poço. Esta profundidade de leitura detecta até 12.000 genes numa única amostra. Embora a sequenciação de RNA possa detectar mais genes, o drug-seq cobre a maioria dos transcritos biologicamente relevantes. Para triagens de alto rendimento, este equilíbrio entre profundidade e eficiência é crucial.
O Drug-seq suporta a análise paralela de centenas ou milhares de tratamentos. A sequenciação de RNA, com os seus requisitos de leitura mais elevados, torna-se frequentemente dispendiosa e demorada em grande escala. O Drug-seq permite um perfilamento rápido sem sacrificar a qualidade dos dados.
-
Drug-seq: 2–13 milhões de leituras por poço, 11.000–12.000 genes detetados
-
Sequenciação de RNA: 30–50 milhões de leituras por amostra, até 17.000 genes detectados.
Os investigadores devem escolher o método que corresponde aos seus objetivos de projeto. Para uma descoberta ampla, a sequenciação de RNA oferece a máxima cobertura. Para triagens e estudos de mecanismos, o drug-seq fornece resultados eficientes e fiáveis.
Comparação de Custos
O custo desempenha um papel importante na seleção do método. A sequenciação de RNA envolve várias etapas, incluindo extração de RNA, preparação de bibliotecas e sequenciação profunda. Cada etapa adiciona ao custo total. O Drug-seq elimina a extração de RNA e utiliza lise direta. Esta alteração reduz as despesas com reagentes e mão de obra.
Em média, o drug-seq custa cerca de 3 dólares por amostra para sequenciação. A sequenciação de RNA pode custar muito mais, especialmente para grandes projetos. A necessidade de uma alta profundidade de leitura e passos de preparação adicionais aumenta as despesas. O fluxo de trabalho simplificado do drug-seq torna a transcriptómica de alto rendimento acessível para a maioria dos laboratórios.
Os investigadores podem analisar mais compostos ou condições com o mesmo orçamento. Esta vantagem acelera a descoberta de medicamentos e apoia a inovação. A eficiência de custo do Drug-seq, combinada com a alta capacidade de processamento, distingue-o do sequenciamento de RNA tradicional.
Nota: Custos mais baixos não significam qualidade inferior. O Drug-seq fornece dados robustos de expressão gênica adequados para análise de mecanismos e descoberta de biomarcadores.
Escolhendo o Método Certo
Selecionar a melhor abordagem para transcriptómica de alto rendimento na descoberta de fármacos depende dos objetivos do projeto, do tipo de amostra e da disponibilidade de recursos. Tanto o Drug-seq como o RNA-seq oferecem poderosos perfis de expressão génica, mas cada método destaca-se em cenários diferentes.
Fatores chave a considerar:
| Critérios | Drug-seq | RNA-seq |
|---|---|---|
| Rendimento | Alto; ideal para ecrãs de grande escala | Moderado; adequado para estudos focados |
| Exemplo de Entrada | Funciona com tão poucos quanto 1.000 células. | Exige quantidades de entrada mais elevadas. |
| Fluxo de trabalho | Lise direta, sem extração de RNA | Necessita de extração e purificação de RNA. |
| Tempo de Resposta | Rápido; resultados em 10 dias úteis | Mais longo devido a etapas de preparação adicionais. |
| Custo | Baixo por amostra | Mais elevado por amostra |
| Profundidade de Dados | Detecta até 12.000 genes. | Detecta até 17.000 genes. |
| Adequação da Aplicação | Triagem, análise de mecanismos, amostras raras | Descoberta profunda, deteção rara de transcritos |
Dica: O Drug-seq simplifica a transcriptómica de alto rendimento para a descoberta de fármacos, especialmente quando os investigadores precisam de rastrear muitos compostos ou trabalhar com material limitado.
Quando escolher o Drug-seq:
-
Triagem de centenas ou milhares de compostos em paralelo.
-
Trabalhar com amostras raras, preciosas ou de baixo input, como organoides ou biópsias clínicas.
-
Necessitando de um perfil de expressão génica com rápida resposta e custo eficaz.
-
Focando no mecanismo de ação, descoberta de biomarcadores ou triagem de toxicidade.
Quando escolher RNA-seq:
-
Exigindo uma cobertura máxima do transcriptoma, incluindo transcritos raros ou novos.
-
Investigação de eventos de splicing complexos ou respostas específicas de isoformas.
-
Realização de estudos aprofundados sobre um número menor de amostras.
Os investigadores em P&D farmacêutica frequentemente selecionam o Drug-seq para descobertas em grande escala e sem viés. O RNA-seq continua a ser valioso para caracterização molecular profunda e validação. A CD Genomics oferece pacotes de serviços flexíveis, permitindo que as equipas ajustem o método aos seus objetivos científicos.
Escolher a plataforma de transcriptómica certa garante um uso eficiente dos recursos e maximiza o impacto dos projetos de descoberta de fármacos.
Aplicações na Descoberta de Fármacos em Neurociência
A descoberta de fármacos em neurociências enfrenta desafios únicos. Os investigadores precisam de ferramentas que consigam lidar com amostras raras, organoides e biópsias clínicas. O Drug-seq oferece soluções escaláveis para a caracterização da resposta a fármacos nestes contextos. A plataforma também apoia estudos em biologia do cancro e tumores, tornando-a valiosa tanto para a investigação em neurociências como em oncologia.
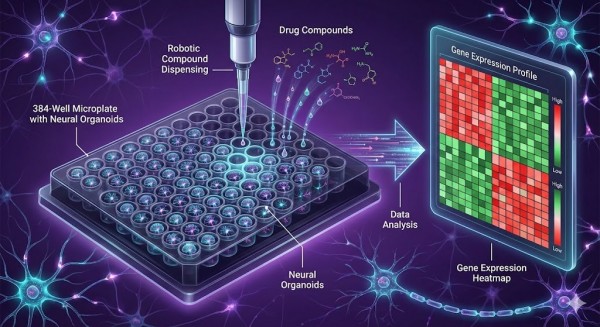
Figura 3: Triagem de Alto Rendimento de Organoides Neurais. O Drug-seq permite o perfilamento de modelos complexos como organoides cerebrais em um formato de 384 poços. Ao analisar assinaturas de expressão génica (Mapa de Calor) em vez de simples alterações fenotípicas, os investigadores podem identificar compostos que modulam vias de doença com alta especificidade.
Triagem de Compostos
O Drug-seq permite alta capacidade de processamento. triagem de compostos na descoberta de fármacos em neurociência. Os cientistas podem testar centenas de moléculas em células neuronais, organoides ou fatias de tecido. O método funciona com tão poucas quanto 1.000 células, o que é ideal para amostras raras. Os investigadores utilizam drug-seq para identificar mudanças na expressão génica após o tratamento. Esta abordagem ajuda a encontrar compostos promissores para estudo adicional.
-
O Drug-seq suporta a triagem paralela de modelos de cancro e tumores.
-
A plataforma detecta mudanças transcriptómicas subtis, revelando os efeitos precoces dos medicamentos.
-
Os cientistas podem comparar respostas entre linhas celulares neurais, cancerígenas e tumorais.
Mecanismo de Ação
Compreender como os medicamentos funcionam é essencial na descoberta de medicamentos em neurociência. O Drug-seq fornece perfis detalhados de expressão genética, ajudando os investigadores a mapear os mecanismos dos medicamentos. A tecnologia revela alterações nas vias em células neuronais, cancerígenas e tumorais. Os cientistas podem ligar assinaturas genéticas específicas à ação dos medicamentos.
-
O Drug-seq revela vias moleculares afetadas por compostos.
-
A plataforma suporta estudos de mecanismos em câncer e organoides tumorais.
-
Os investigadores utilizam a análise de vias para prever a eficácia e a segurança dos medicamentos.
Q: Que insights o drug-seq oferece sobre o mecanismo de ação?
A: O Drug-seq identifica redes e vias genéticas alteradas por fármacos em modelos neurais e tumorais.
Fora do Alvo e Toxicidade
O Drug-seq destaca-se na deteção de efeitos fora do alvo e toxicidade na descoberta de fármacos em neurociência. A plataforma analisa as alterações na expressão génica ligadas a reações adversas. Os investigadores utilizam conjuntos de dados curados para prever a toxicidade em células neuronais, cancerígenas e tumorais.
| Descrição da Evidência | Detalhes |
|---|---|
| Deteção de alterações na expressão génica pelo Drug-seq | O Drug-seq deteta alterações subtis na expressão génica ligadas à toxicidade, reduzindo falhas em estágios avançados. |
| Perfilagem fora do alvo para avaliação de segurança | Os resultados da previsão de efeitos fora do alvo para qualquer molécula servem como uma representação molecular, capturando efeitos fora do alvo e subsequentes de reações adversas a medicamentos (RAM) ou toxicidade. |
| Conjunto de dados para previsão de toxicidade | Um conjunto de dados curado inclui 877 compostos tóxicos e 1229 compostos não tóxicos, formando a base para uma abordagem de previsão de toxicidade baseada em alvos não específicos. |
| Resultados da visualização UMAP | A visualização UMAP ilustrou uma discriminação mais clara entre compostos seguros e inseguros com base na representação de alvos fora do alvo. |
| Desempenho do classificador de toxicidade | O LightGBM demonstrou um desempenho superior na previsão de toxicidade em comparação com outros modelos de aprendizagem automática. |
Os investigadores visualizam perfis de segurança utilizando gráficos UMAP. Modelos de aprendizagem automática, como o LightGBM, melhoram a precisão na previsão de toxicidade.
Estudo de Caso Hit-to-Lead
Um estudo recente utilizou drug-seq para rastrear organoides neurais na otimização de hits para leads. Os cientistas identificaram compostos que modulavam vias neurais sem afetar marcadores de câncer ou tumor. A equipa validou os hits utilizando dados transcriptómicos e análise de vias (Ye et al., 2018). O drug-seq permitiu a seleção rápida de leads seguros e eficazes para desenvolvimento adicional.
O Drug-seq apoia a descoberta de medicamentos em neurociência, a investigação do câncer e a medicina personalizada. A plataforma trabalha com amostras raras, organoides e projetos de investigação clínica.
Q: Pode o drug-seq ajudar a selecionar candidatos a fármacos mais seguros?
A: Sim. O Drug-seq deteta sinais fora do alvo e de toxicidade em células neuronais, cancerígenas e tumorais, orientando a seleção de hits para leads.
Análise de Dados e Bioinformática
De Leituras a Matrizes
O Drug-seq produz um alto-dimensional leitura que captura alterações na expressão génica em muitas amostras. A jornada de análise de dados começa com leituras de sequenciamento brutas. Os analistas primeiro limpam os dados, removendo sequências de baixa qualidade e fragmentos de adaptadores. Em seguida, alinham o leituras limpas para um transcriptoma de referência utilizando ferramentas como STAR ou HISAT2. Este passo assegura que cada leitura corresponda ao gene ou transcrito correto. Após o alinhamento, verificações de controlo de qualidade removem leituras mal mapeadas. O passo final conta quantas leituras se mapeiam a cada gene, criando uma matriz de contagem bruta. Esta matriz forma a base para toda a análise subsequente.
A matriz de contagem fornece uma instantânea da atividade génica para cada amostra, tornando possível comparar os efeitos dos fármacos entre experimentos.
Análise DGE
A análise de expressão gênica diferencial (DGE) ajuda os cientistas a identificar quais genes respondem a tratamentos com medicamentos. Os conjuntos de dados de Drug-seq frequentemente utilizam métodos estatísticos adaptados a partir de sequenciação de RNA de célula única. Estes métodos lidam com a distribuição única das contagens de códigos de barras moleculares. Os analistas escolhem entre abordagens paramétricas e não paramétricas. Os modelos paramétricos incluem o modelo Binomial Negativo Inflacionado a Zero e os modelos Hurdle. Estes modelos consideram os zeros excessivos e a variabilidade nos dados. Os pacotes R populares para estes métodos incluem MAST e ZINB-wave. As ferramentas não paramétricas, como D3E e EMDomics, oferecem flexibilidade para comparar dois grupos. Cada método ajuda os investigadores a detectar alterações significativas na expressão génica com confiança.
-
Métodos paramétricos: Lidam com distribuições de dados complexas, adequados para grandes conjuntos de dados.
-
Métodos não paramétricos: Úteis para comparações simples entre grupos, robustos a valores atípicos.
Perspectivas de Vias e Redes
Uma vez que a análise de DGE identifica genes-chave, a análise de vias e redes revela o significado biológico. Os analistas utilizam ferramentas de enriquecimento para mapear genes diferencialmente expressos a vias conhecidas. Este processo revela quais processos celulares os medicamentos afetam mais. A análise de redes liga genes em módulos funcionais, mostrando como os tratamentos com medicamentos remodelam as redes celulares. Esses insights ajudam os pesquisadores a entender os mecanismos de ação e a prever efeitos fora do alvo. O drug-seq permite a descoberta rápida de alterações nas vias, apoiando a identificação de biomarcadores e a validação de alvos.
A análise de vias transforma dados brutos em conhecimento acionável, orientando decisões de desenvolvimento de medicamentos.
Implementação: Interna vs. Terceirização
As equipas farmacêuticas frequentemente enfrentam a escolha entre executar fluxos de trabalho de drug-seq interno ou externalização para um prestador de serviços especializado. Esta decisão impacta a velocidade do projeto, a qualidade dos dados e a alocação de recursos. O Drug-seq oferece transcriptómica escalável para a descoberta de fármacos, mas barreiras técnicas podem afetar a implementação.
Barreiras Técnicas
Necessidades de Equipamento
Configurar o drug-seq internamente requer equipamento de laboratório avançado. As equipas precisam de manipuladores de líquidos automatizados, sequenciadores de alto rendimento e sistemas de armazenamento de dados robustos. Muitos laboratórios também necessitam de software especializado para rastreamento de amostras e análise de dados. Esses investimentos podem ser significativos, especialmente para grupos com orçamentos ou espaço limitados. A manutenção e calibração acrescentam custos contínuos. Nem todos os grupos de investigação conseguem justificar essas despesas para projetos ocasionais.
Efeitos de Lote
Os efeitos de lote podem introduzir variabilidade indesejada nos dados de transcriptómica. O manuseio inconsistente de amostras, lotes de reagentes ou o desempenho de instrumentos podem causar estes efeitos. Os fluxos de trabalho de Drug-seq exigem um controlo de qualidade rigoroso para minimizar as diferenças entre lotes. As equipas internas devem padronizar protocolos e monitorizar cada passo. Mesmo pequenas desvios podem impactar a análise e interpretação subsequentes.
Nota: A subcontratação a um prestador experiente ajuda a controlar os efeitos de lote através de fluxos de trabalho validados e processamento centralizado.
Benefícios dos Prestadores de Serviços
As organizações de investigação contratadas (CROs) como a CD Genomics oferecem várias vantagens. Elas proporcionam acesso a equipamentos de última geração e pessoal especializado. As suas equipas seguem protocolos validados, reduzindo a variabilidade técnica. Os prestadores de serviços oferecem tempos de resposta rápidos, frequentemente dentro de 10 dias úteis para projetos padrão de drug-seq. O suporte dedicado em bioinformática garante uma análise e relatórios de dados precisos.
A CD Genomics destaca-se com pacotes de serviços flexíveis. Os investigadores podem escolher opções de transcritos padrão, de ultra-baixa entrada ou de comprimento total. Soluções personalizadas atendem a necessidades únicas de projetos, como amostras raras ou organoides. A externalização permite que as equipas se concentrem no design experimental e na interpretação, em vez de na configuração técnica.
Métricas de Seleção de CRO
Selecionar o CRO certo envolve uma avaliação cuidadosa. Os principais métricas incluem:
-
ExperiênciaProcure fornecedores com um histórico comprovado em drug-seq e transcriptómica de alto rendimento.
-
Tempo de RespostaA entrega rápida de dados acelera a tomada de decisões.
-
Qualidade dos DadosAvaliar medidas de controlo de qualidade e apoio em bioinformática.
-
Flexibilidade de ServiçoPacotes flexíveis e soluções personalizadas acomodam diversas necessidades de pesquisa.
-
ComunicaçãoO suporte responsivo garante uma gestão de projeto suave.
| Métrico | Importância | Oferta da CD Genomics |
|---|---|---|
| Experiência | Garante resultados fiáveis | Experiência extensiva em drug-seq |
| Qualidade dos Dados | Garante dados robustos e reproduzíveis. | Equipa dedicada de QC e bioinformática |
| Flexibilidade | Corresponde à escala do projeto e ao tipo de amostra. | Múltiplos pacotes, soluções personalizadas |
| Comunicação | Suporta colaboração e resolução de problemas. | Apoio direto à gestão de projetos |
Dica: Fazer parceria com uma CRO como a CD Genomics simplifica a implementação do drug-seq e maximiza o impacto da pesquisa.
Futuro da Triagem Transcriptómica
A transcriptómica continua a transformar a descoberta de medicamentos. Tecnologia Drug-seq A CD Genomics lidera esta mudança. Os investigadores agora utilizam a transcriptómica para perfilar a expressão génica de forma rápida e económica. O Drug-seq permite triagens de alto rendimento, análise de mecanismos e descoberta de biomarcadores. Estes avanços apoiam a medicina personalizada e aceleram a investigação farmacêutica.
As principais tendências que moldam o futuro da triagem transcriptómica incluem:
-
Automação e Miniaturização:
Os laboratórios investem em plataformas automatizadas. Estes sistemas lidam com milhares de amostras com mínima intervenção humana. Fluxos de trabalho miniaturizados reduzem o uso de reagentes e diminuem custos. O Drug-seq já elimina a extração de RNA, estabelecendo um padrão para processos simplificados. -
Integração de Inteligência Artificial (IA):
Ferramentas de IA analisam grandes conjuntos de dados de transcriptómica. Modelos de aprendizagem automática preveem respostas a medicamentos e identificam biomarcadores. Os investigadores utilizam IA para descobrir padrões ocultos na expressão génica. Dados de drug-seq suportam estas análises avançadas. -
Transcriptómica de Célula Única e Espacial:
Cientistas exploram a expressão genética com resolução a nível de célula única. A transcriptómica espacial mapeia a atividade genética dentro dos tecidos. Estes métodos revelam a heterogeneidade celular e a arquitetura dos tecidos. O drug-seq adapta-se a amostras de baixo input, tornando-se compatível com organoides e espécimes raros. -
Medicina Personalizada:
A triagem transcriptómica adapta a seleção de medicamentos a pacientes individuais. Os investigadores combinam perfis de expressão génica com terapias direcionadas. O Drug-seq permite a caracterização rápida de amostras clínicas, apoiando a medicina de precisão.
Nota: A flexibilidade e escalabilidade do Drug-seq posicionam-no como uma tecnologia fundamental para a descoberta de novos fármacos no futuro.
Estudo de caso:
Um estudo recente utilizou o Drug-seq para rastrear organoides neurais em resposta a fármacos (Ye et al., 2018). A equipa identificou compostos que modulavam vias neurais sem afetar marcadores de cancro. Esta abordagem acelerou a seleção de potenciais candidatos e melhorou a avaliação de segurança.
| Direção Futura | Impacto na Descoberta de Medicamentos |
|---|---|
| Automação | Triagem mais rápida e fiável |
| Integração de IA | Descoberta melhorada de biomarcadores e alvos |
| Técnicas de Célula Única | Insights mais profundos sobre populações celulares |
| Medicina Personalizada | Terapias personalizadas para pacientes |
Os investigadores esperam que a triagem transcriptómica se torne ainda mais acessível. A redução de custos e os tempos de resposta mais rápidos impulsionarão a adoção. O Drug-seq da CD Genomics continuará a apoiar a inovação na investigação e desenvolvimento farmacêutico. Os cientistas utilizarão a transcriptómica para responder a questões complexas e desenvolver medicamentos mais seguros e eficazes.
O drug-seq da CD Genomics remove barreiras na descoberta de medicamentos. A plataforma acelera a pesquisa, aumenta a escalabilidade e reduz custos. Os cientistas utilizam o drug-seq para a descoberta de biomarcadores em projetos grandes e pequenos. A tecnologia melhora a qualidade dos dados e apoia a descoberta de biomarcadores em amostras raras. As equipas obtêm insights mais profundos na análise de mecanismos e na descoberta de biomarcadores para a medicina personalizada. Os avanços futuros no drug-seq impulsionarão a inovação na pesquisa farmacêutica.
Perguntas Frequentes
Q: Que tipos de amostras o Drug-seq suporta?
O Drug-seq da CD Genomics trabalha com lisados celulares, organoides e fatias de tecido. Os investigadores podem usar apenas 1.000 células. A plataforma suporta transcriptómica de alto rendimento para amostras raras ou preciosas.
P: O Drug-seq pode detectar alterações subtis na expressão génica?
Sim. O Drug-seq perfila milhares de genes por amostra. O método detecta alterações transcriptómicas subtis após o tratamento com o fármaco. Os investigadores utilizam estes dados para análise de mecanismos e descoberta de biomarcadores.
Q: Como é que o Drug-seq se compara ao RNA-seq tradicional?
O Drug-seq elimina a extração de RNA e utiliza lise direta. Esta abordagem reduz custos e o tempo de manuseio. O Drug-seq suporta triagens de alto rendimento, enquanto o RNA-seq tradicional oferece uma cobertura mais profunda para estudos focados.
P: O Drug-seq é adequado para amostras de baixo input ou clínicas?
Absolutamente. O Drug-seq pode analisar amostras com apenas 1.000 células. Esta característica torna-o ideal para organoides, espécimes clínicos raros e pequenas biópsias de tecido.
Q: Que suporte em bioinformática é fornecido pela CD Genomics?
A CD Genomics oferece uma análise bioinformática abrangente. A equipa fornece matrizes de contagem de genes, resultados de expressão diferencial e insights sobre vias metabólicas. Os investigadores recebem relatórios claros e acionáveis.
P: O Drug-seq pode ser utilizado para pesquisa em medicina personalizada?
Sim. O Drug-seq permite o perfilamento rápido da expressão génica a partir de amostras clínicas. Os investigadores utilizam estes dados para identificar biomarcadores e apoiar estratégias de medicina personalizada.
P: O Drug-seq pode analisar amostras de baixo input, como organoides ou espécimes clínicos raros?
Drug-seq A CD Genomics suporta transcriptómica de alto rendimento com entradas muito baixas. Os investigadores podem perfilar a expressão génica a partir de apenas 1.000 células. Esta característica torna o Drug-seq ideal para amostras raras, organoides ou pequenos cortes de tecido. A plataforma preserva a integridade do RNA ao evitar a extração. Os cientistas podem utilizar o Drug-seq para projetos onde o material da amostra é limitado.
Q: Que tipos de amostras funcionam melhor com o Drug-seq?
O Drug-seq funciona com lisados celulares, organoides e cortes de tecido. O método não requer RNA purificado. Esta flexibilidade permite que os investigadores estudem uma ampla gama de modelos biológicos. O Drug-seq adapta-se a projetos de entrada padrão e de ultra-baixa entrada.
Dica: O serviço de ultra-baixa entrada do Drug-seq ajuda as equipas a maximizar os dados de amostras preciosas ou raras.
Q: Como é que o Drug-seq difere da sequenciação de RNA de célula única (scRNA-seq)?
O Drug-seq perfila populações celulares em massa, não células individuais. Esta abordagem permite a triagem em alta capacidade de centenas ou milhares de amostras em paralelo. O scRNA-seq analisa a expressão gênica ao nível de célula única. Fornece uma heterogeneidade celular detalhada, mas requer fluxos de trabalho mais complexos e custos mais elevados.
| Recurso | Drug-seq | scRNA-seq |
|---|---|---|
| Requisito de Entrada | 1.000+ células por amostra | Células individuais |
| Rendimento | Centenas a milhares de poços | Dezenas a centenas de células |
| Custo por Amostra | Baixo | Mais alto |
| Saída de Dados | Matriz de expressão génica em massa | Resolução a nível de célula única |
Q: Quando devem os investigadores escolher o Drug-seq em vez do scRNA-seq?
O Drug-seq é adequado para triagens de compostos em grande escala, estudos de mecanismos e projetos com material limitado. O scRNA-seq é mais apropriado para estudos focados na heterogeneidade celular ou em tipos celulares raros. O Drug-seq oferece um tempo de resposta mais rápido e custos mais baixos para transcriptómica de alto rendimento.
Q: Como é que o drug-seq melhora a triagem de compostos em neurociência?
A: O Drug-seq permite uma análise rápida e imparcial da expressão génica em células neuronais e tumorais, mesmo com uma entrada baixa.
Referência
-
Ye, C., Ho, D.J., Neri, M. et al. DRUG-seq para perfilagem transcriptómica miniaturizada de alto rendimento na descoberta de fármacos. Nat Commun nove , 4307 (2018).
-
Li J, Ho DJ, et al. O DRUG-seq Fornece Leituras de Atividade Biológica Não Tendenciosas para a Descoberta de Fármacos em Neurociência. ACS Chem Biol. 2022 Jun 17;17(6):1401-1414. doi: 10.1021/acschembio.1c00920. Epub 2022 May 4. PMID: 35508359; PMCID: PMC9207813.
-
Subramanian, A., Narayan, R., Corsello, S. M., et al. (2017). Um Mapa de Conectividade de Nova Geração: Plataforma L1000 e os Primeiros 1.000.000 Perfis. Célula, 171(6), 1437-1452.e17.
-
Ziegenhain, C., Vieth, B., Parekh, S., et al. (2017).Análise Comparativa de Métodos de Sequenciação de RNA de Célula Única. Célula Molecular, 65(4), 631-643.e4.
-
Norkin M, Huelsken J. TORNADO-seq: Um Protocolo para Triagem de Fármacos Baseada em RNA-seq Direcionada de Alto Rendimento em Organoides. Métodos Mol Biol. 2023;2650:65-75. doi: 10.1007/978-1-0716-3076-1_6. PMID: 37310624.
-
Amor, M. I., Huber, W., & Anders, S. (2014). Estimativa moderada da mudança de dobra e dispersão para dados de RNA-seq com DESeq2. Genome Biology, 15(12), 550.
Para mais informações sobre Drug-seq, transcriptómica de alto rendimento e serviços da CD Genomics, visite o oficial Página Drug-seq da CD Genomics.


